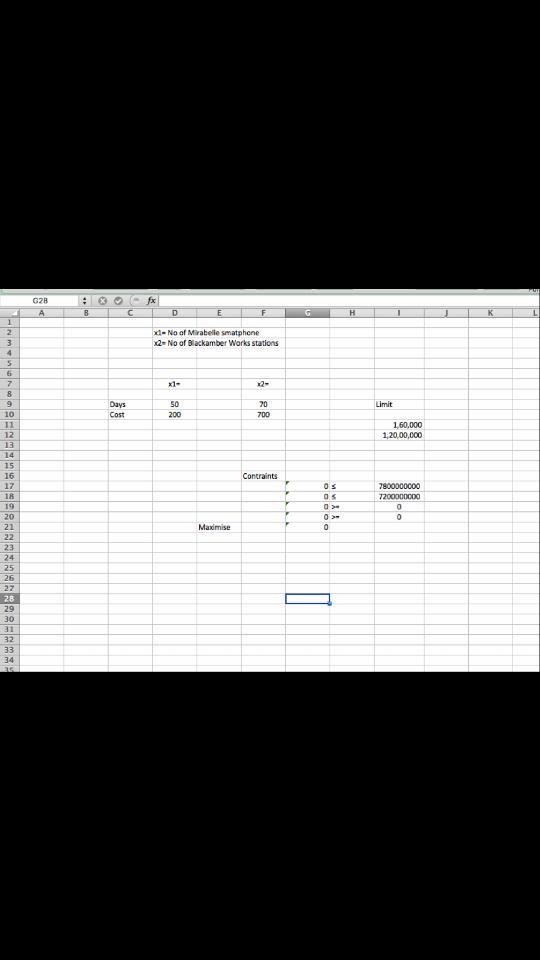
Answer:
Refer to the explanation
Explanation:
Number of Mobiles=x1
Number of Workstations=x2
Constraints:
50x1 + 70x2 <= 1,60,000
250x1 + 700x2 <= 12,000,000
x1 >= 0 x2 >= 0
Objective function N(x1, x2) = 7800000000 x1 + 7200000000 x2
Excel formulae:
G17 = D9 * E7 + F9 * G7
G18= D10 * E7 * F10 * G7
G19= E7
G20= G7
G21= I17 * E7 + I18 * G7 (This will yield the Maximum)
And E7 and G7 will be the solution.
Set up your sheet as shown in the diagram and apply the formulas.
Access the tool and select solver. Upon opening the Solver dialog, confirm ‘Assume Linear model’ and ‘assume non-negative’. Click to solve the model and keep the solution.
What if the offshore team members are unable to join the iterations demonstration because of timezone or infrastructure issues? (c) Not a significant problem. The offshore lead and the onsite team members will attend the demo with the product owner and can relay the feedback to the offshore team afterwards.
Explanation:
Not a significant problem. The offshore lead and the onsite team members will attend the demo with the product owner and can relay the feedback to the offshore team afterwards.
From the previous statement, it is evident that if offshore team members cannot attend the demo alongside the product owner due to issues with time zones or infrastructure, it won't pose a major concern because the onsite team will be present and can share all relevant insights and feedback with the offshore team. They all belong to the same team.
Therefore, the answer (3) is correct
#include <iostream>
using namespace std;
void OutputMinutesAsHours(double origMinutes) {
double hours = origMinutes / 60.0;
cout << hours;
}
int main() {
OutputMinutesAsHours(210.0); // This function will also be called with 3600.0 and 0.0.
cout << endl;
return 0;
}
The lines highlighted in bold perform the conversion from minutes to hours by dividing the input minutes by 60, since there are 60 minutes in one hour. The parameter origMinutes is a double, so the division uses 60.0 to keep consistent data types. Running this code with 210.0 will output 3.5.
Answer:
The Python program is outlined below.
Explanation: